
Sharding-JDBC
简介
sharding-jdbc是ShardingSphere的其中一个模块
ShardingSphere
一套开源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar(计划中)这3款相互独立的产品组成。 他们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如Java同构、异构语言、容器、云原生等各种多样化的应用场景
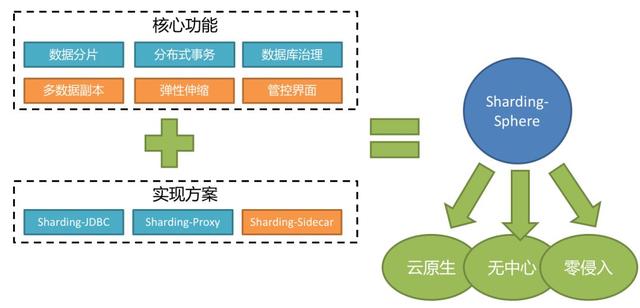
ShardingSphere功能一览
| 功能分类 | 具体功能 |
|---|---|
| 基础 | 数据分片、分库&分表、读写分离、分片策略定制化、无中心化分布式主键 |
| 分布式事务 | 标准化事务接口、XA强一致性事务、柔性事务、数据库治理 |
| 分布式治理 | 弹性伸缩、可视化链路追踪、数据加密 |
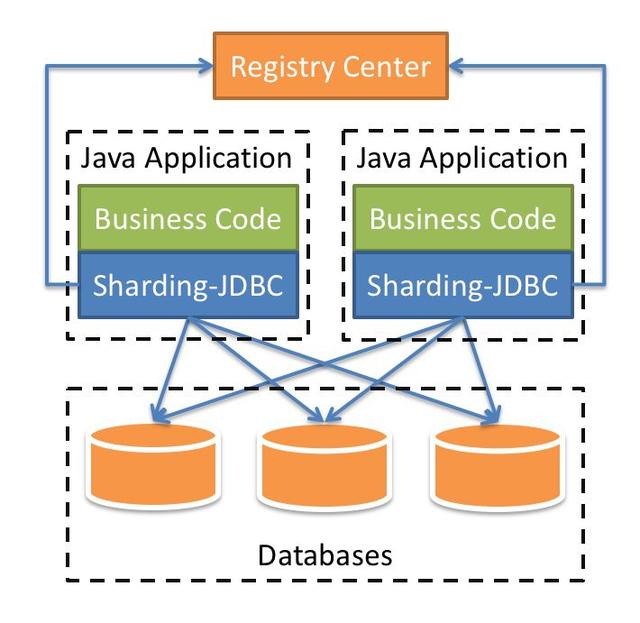
Sharding-JDBC
一个轻量级Java框架,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库,以jar包形式提供服务(耦合在Java代码中),无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架
适用的ORM框架:JPA, Hibernate, Mybatis, Spring JDBC Template
支持的数据库:MySQL,Oracle,SQLServer和PostgreSQL
Sharding-Proxy
一个分布式数据库中间件,定位为透明化的数据库代理端。作为开发人员可以完全把它当成数据库,而它具体的分片规则在Sharding-Proxy中配置;解决了Sharding-JDBC的一部分耦合问题
#####
Sharding-JDBC——读写分离——Demo
建立MySQL主从复制模型
参考:https://www.ziruchu.com/art/69
建立SpringBoot项目,添加Maven依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.5.0</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>cn.waston</groupId>
<artifactId>test_sharding_jdbc</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>test_sharding_jdbc</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
<sharding-sphere.version>4.0.0-RC1</sharding-sphere.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.1.4</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.12</version>
<scope>runtime</scope>
</dependency>
<!--sharding-->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>${sharding-sphere.version}</version>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-core-common</artifactId>
<version>${sharding-sphere.version}</version>
</dependency>
<!--druid-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.21</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>
定义配置文件
server:
port: 8083
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
# 显示sql
props:
sql:
show: true
# 配置数据源
datasource:
# 给每个数据源取别名
names: ds1,ds2
# 给每个数据源配置数据库连接信息
ds1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3307/test?useUnicode=true&characterEncoding=utf-8&allowMultiQueries=true&useSSL=false&serverTimezone=UTC
username: root
password: 123456
maxPoolSize: 100
minPoolSize: 5
ds2:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3308/test?useUnicode=true&characterEncoding=utf-8&allowMultiQueries=true&useSSL=false&serverTimezone=UTC
username: root
password: 123456
maxPoolSize: 100
minPoolSize: 5
# 配置默认数据源ds1
sharding:
# 默认数据源 如果不配置 进行写、改、删操作时会报错
default-data-source-name: ds1
# 配置读写分离 主从复制是前提
masterslave:
# 配置主从名称
name: ms
# 配置主库 负责写入
master-data-source-name: ds1
# 配置从库 负责读取 多个从节点用“,”分隔
slave-data-source-names: ds2
# slave节点的负载均衡策略 轮询
load-balance-algorithm-type: round_robin
mybatis:
mapper-locations: classpath:mapper/*.xml
type-aliases-package: cn.waston.test_sharding_jdbc.entity
业务代码
@Mapper
public interface UserMapper {
@Insert("insert into user(nick_name, password, sex, birthday) values(#{nickName}, #{password}, #{sex}, #{birthday})")
void addUser(User user);
@Select("select * from user")
List<User> findUsers();
}
@RestController
@RequestMapping("/user")
public class UserController {
@Resource
private UserMapper userMapper;
@GetMapping("/save")
public String insert(){
User user = new User();
user.setNickName("sam" + new Random().nextInt());
user.setPassword("123456");
user.setSex(1);
user.setBirthday(new Date());
userMapper.addUser(user);
return "success";
}
@GetMapping("/listuser")
public List<User> listuser(){
return userMapper.findUsers();
}
}
分库、分表
当我们的数据达到了很大的量,如千万级、亿级,单表查询的效率就会变的很低,整个数据库的读取压力也会变的很大。业内解决这一问题的做法通常是:分库、分表
分库、分表可分为两类
- 水平拆分:同一个表的数据拆到不同的库/不同的表中去(表结构一致)。可以根据时间、地区或某个业务维度拆分,也可以通过hash进行拆分,最后通过路由访问到具体的数据
- 垂直拆分:把一个有很多字段的表拆分成多个表/多个库中去(每个表的结构都不一样)。通常根据业务纬度进行拆分,如订单表可以拆分为订单地址表、订单商品表等;也可以根据数据“冷热”程度拆分,热点字段放到一个表,其余的放到另外的表
ShardingJDBC分库分表Demo
将项目的配置文件改为如下:
server:
port: 8083
mybatis:
mapper-locations: classpath:mapper/*.xml
type-aliases-package: cn.waston.test_sharding_jdbc.entity
spring:
main:
allow-bean-definition-overriding: true
shardingsphere:
# 显示sql
props:
sql:
show: true
# 配置数据源
datasource:
# 给每个数据源取别名
names: ds0,ds1
# 给每个数据源配置数据库连接信息
ds0:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3307/test?useUnicode=true&characterEncoding=utf-8&allowMultiQueries=true&useSSL=false&serverTimezone=UTC
username: root
password: 123456
maxPoolSize: 100
minPoolSize: 5
ds1:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3308/test?useUnicode=true&characterEncoding=utf-8&allowMultiQueries=true&useSSL=false&serverTimezone=UTC
username: root
password: 123456
maxPoolSize: 100
minPoolSize: 5
# 配置默认数据源ds1
sharding:
# 默认数据源 如果不配置 进行写、改、删操作时会报错
default-data-source-name: ds0
# 配置分表规则
tables:
# 逻辑表名
user:
# 数据节点 数据源$->{0..N} 逻辑表名$->{0..N}
actual-data-nodes: ds$->{0..1}.user$->{0..1}
# 拆分库策略
database-strategy:
inline:
sharding-column: age
algorithm-expression: ds$->{age % 2}
# 拆分表策略
table-strategy:
inline:
sharding-column: age #分片键
algorithm-expression: user$->{age % 2} #分片算法表达式
效果:在新增一条User表的记录时,Sharding会去计算age模2的值,进而通过上面设定的逻辑,改写SQL语句,将值插入到对应的表中去
如果同时需要进行读写分离,可以这样设定配置文件(取消了分库操作):
sharding:
master-slave-rules:
ms0:
master-data-source-name: ds0
slave-data-source-names: ds1
tables:
user:
actual-data-nodes: ms0.user$->{0..1}
table-strategy:
inline:
sharding-column: age
algorithm-expression: user$->{age % 2}
若按生日进行分表,比如2000年前放一个表,其余的放另一个,则需要先创建一个分表逻辑类:
package cn.waston.test_sharding_jdbc.algorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingValue;
import java.util.*;
public class BirthdayAlgorithm implements PreciseShardingAlgorithm<Date> {
List<Date> dateList = new ArrayList<>();
{
Calendar calendar1 = Calendar.getInstance();
calendar1.set(2000, 1, 1, 0, 0, 0);
Calendar calendar2 = Calendar.getInstance();
calendar2.set(3000, 1, 1, 0, 0, 0);
dateList.add(calendar1.getTime());
dateList.add(calendar2.getTime());
}
/**
*
* @param availableTargetNames 数据源集合(库或表)
* @param shardingValue 分片值
* @return 返回 ds0、ds1
*/
@Override
public String doSharding(Collection<String> availableTargetNames, PreciseShardingValue<Date> shardingValue) {
// 获取属性数据库的值
Date date = shardingValue.getValue();
// 获取数据源的名称信息列表
Iterator<String> iterator = availableTargetNames.iterator();
String target = null;
for(Date s : dateList){
target = iterator.next();
// 如果数据晚于指定的日期 结束循环
if(date.after(s)){
break;
}
}
return target;
}
}
配置文件改为:
sharding:
master-slave-rules:
ms0:
master-data-source-name: ds0
slave-data-source-names: ds1
tables:
user:
actual-data-nodes: ms0.user$->{0..1}
table-strategy:
standard:
shardingColumn: birthday
preciseAlgorithmClassName: cn.waston.test_sharding_jdbc.algorithm.BirthdayAlgorithm
表还可以按日期划分,如user202001、user202112,做法如下:
tables:
user:
key-generator:
column: id
type: SNOWFLAKE
actual-data-nodes: ms0.user_$->{2021..2022}${(6..6).collect{t ->t.toString().padLeft(2,'0')}}
table-strategy:
inline:
shardingColumn: password
algorithmExpression: user_$->{password}
PS:分库分表后,id生成策略应设置为SNOWFLAKE、UUID等全局唯一id
事务管理
为保证数据库的一致性原则,通常需要在程序中开启事务功能,如加在方法上的@Transactional(rollbackFor = Exception.class)。而在分布式调用场景中,由于没法回滚远程调用,故依然存在一致性风险。但ShardingJDBC拥有不错的解决方案
项目中增加依赖:
<dependency>
<groupId>io.shardingsphere</groupId>
<artifactId>sharding-transaction-spring-boot-starter</artifactId>
<version>3.1.0</version>
</dependency>
在方法上添加@ShardingTransactionType(TransactionType.XA)即可开启分布式事务